前のページへ
2022年ファイナンス・ワークショップ

11月11日にファイナンス・ワークショップをオンライン形式で開催しました。8回目の開催となった今回のワークショップでは、「機械学習のファイナンス分析への応用」を取り上げました(プログラム)。
1. 開会挨拶

開会挨拶で副島豊(金融研究所長)は、飛躍的に発展しているデータの利用可能性と新しい分析手法の組み合わせが、様々なイノベーションをもたらしていると指摘しました。

主要中央銀行のリサーチ実務においても新しいデータと分析手法の活用が進んでいることを日本銀行の事例(参考文献1)も交えて紹介し、家計や企業の認識や判断、行動などのリアリティに肉薄することが可能になりつつあるとの期待を示しました。
以下では、3本の研究報告の内容を紹介します。
2. テキスト分析を用いた気候変動の影響に関する研究報告

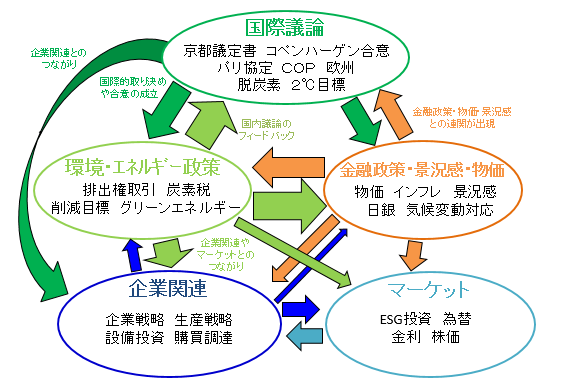
金田規靖(日本銀行)は、気候変動問題に自然言語処理を応用した分析を紹介しました(坂地泰紀氏<東京大学>との共同研究、 資料2)。気候変動問題が新聞ニュース記事においてどのような「経済ナラティブ」(経済事象とその原因事象についての物語)を形成しているのか、その定量化・可視化を行いました。
新聞記事や企業レポートに含まれるテキスト情報には、統計データからは抽出できない「つながり」や「因果関係」が含まれています。しかも、A→Bという因果のコンテクストとは別の記事でB→Cという因果が語られていた場合、そのメディアではA→B→Cというナラティブが示されていることになります。例えば、気候変動の国際会議→国際基準・規制・合意→企業の対応、というナラティブが考えられます。
こうしたつながりを捕捉するためには、ある記事や文章からA→Bという因果ナラティブを発見するだけでなく、トピックが同じとは限らない別の記事・文章で登場するBおよびB→Cという因果ナラティブを把握し、両者がBでつながっていることを確認する必要があります。
具体的には、二つの手法を組み合わせています。まず、 Devlin, Change, Lee, and Toutanova (2018) (参考文献 2)で提案された最新の自然言語処理モデル「BERT(Bidirectional Encoder Representations from Transformers)」を用いて、テキストの文脈を踏まえつつ、気候変動に関連した「国際議論」「政策」「企業関連」といったトピックの分類を行います。
次に、Sakaji, Sekine, and Masuyama (2008) (参考文献 3)で提唱した「因果抽出」という手法を用いて、テキスト上の原因と結果を抽出しています。分析結果を組み合わせることで、「国際的な議論の活発化⇒政策の推進・企業行動の変化」といった経済ナラティブをニュースから見つけ出し、指数やネットワーク図として可視化することができるようになります。
分析の結果、2000年代の「国際会議や規制」の議論は他のトピックへ波及しない傾向があったが、近年は、「国際会議や規制→企業の事業戦略・設備投資」という因果関係や「国際会議や規制→金融政策・景況感・物価」というつながりが確認できるなど、気候変動に関するナラティブの変化が確認できました。

指定討論者の新谷元嗣氏(東京大学)は、特定のテーマに関するトピック間の因果情報という、新しいタイプのデータを経済分析に利用した、意欲的な取組みと評価しました。一方、気候変動に関する「経済ナラティブ」を指数化した場合、その上昇や下落は何を意味するのか、と問いました。金田は、指数の上昇は、気候変動リスクへの関心の高まりや、企業の対応行動の活発化を示唆している、との解釈を示しました。
報告者らが今回提案した手法は、討論者が指摘したとおり新規性が高く、かつ気候変動の分析に限らず、幅広い分析に応用することが可能です。例えば、企業や家計、金融市場に関するテキスト情報を分析することで、景況感や物価、資産価格に関する将来予想の形成に新たなナラティブが発見されるかもしれません。現状を経済主体がどう認識しているかの把握にも有効そうです。この新たな手法が、様々な研究課題の解明や理論構築に新たな視座を与えることが期待されます。
3. 機械学習モデルの解釈に関する研究報告

機械学習モデルによる予測結果の分析・解釈手法として注目を集めている「SHAP(SHapley Additive exPlanations)」と呼ばれる手法があります。金田規靖(日本銀行)は、これを原油価格の予想に用いた研究を報告しました(資料3)。
機械学習モデルは、多くの変数における複雑な関係を表現することができるため、幅広い分野での活用が進んでいます。もっとも、モデルが複雑化したり変数が増加したりすると、予測精度が向上する反面、結果の説明可能性が失われる傾向があります。
この問題への対応として、Lundberg and Lee (2017) (参考文献 4)によりSHAPというモデル説明手法が提案されました。SHAPを利用すると、多くの説明変数からなる複雑な機械学習モデルであっても、「被説明変数の動きが、どの説明変数の動きにどの程度起因するのか」という変動要因の定量化・可視化・変動要因同士の重要度の比較といった検証が可能となります。「なぜ、そう予測したのか」をモデルに沿って説明できるようになります。
SHAPを機械学習モデルによる原油価格の予測結果に適用したところ、原油の需給バランスやマーケット要因の影響を受けやすいことが示唆されました。また、それぞれの要因の影響度が、時間を通じてダイナミックに変化することも示されました。
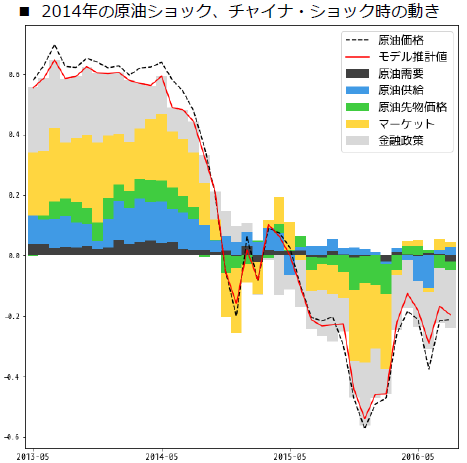
一方で、モデルで使用する説明変数をやみくもに増やすと、予測精度は向上するものの、特定の「変動要因」の寄与が金融・経済の常識とは反対方向に作用したり、異様に大きくなったりするといった結果も観察されました。説明はしているが解釈が難しいという悩ましい現象です。
これは、モデルの外にある専門的知識によってモデルの結果を検証していくことの重要性を示唆しています。また、解釈可能性がモデル選択(ここでは変数選択)の妥当性評価にも有益であることを示唆しているのかもしれません。

指定討論者の大橋和彦氏(一橋大学・東京工業大学)は、SHAPを用いたモデルの検証手順等が分かりやすく示されていて、実務的に有益な研究であると評価しました。論点として、モデルの結果の検証にあたり留意すべきことは何か、といった実務面の課題や、時間経過によって生じうるデータの構造変化をどう扱うかといった点を指摘しました。
報告者らが開発した手法は、これまで予測精度の向上に偏りがちだった機械学習モデルを、モデルの予測精度と予測結果の説明可能性という双方の観点から評価することを可能にする、画期的なツールであり、討論者が述べたように、実務への貢献も大きいといえます。
もっとも、こうした説明可能性が、因果関係とは必ずしも同じものではないことに注意する必要があります。因果関係の特定は、機械学習モデルを含め、経済・ファイナンス研究が、長年直面してきた課題であり、近年新たな手法が登場しています。こうしたものとの組み合わせも有効そうであり、引き続き、研究の発展が待たれます。
4. 深層学習のファイナンス分析への応用に関する研究報告

篠崎裕司(日本銀行主査)は、深層学習のファイナンス分野への応用について、「ディープ・ヘッジング」と呼ばれる最先端の技術について解説し、今後の研究の方向性を展望しました(資料4)。
金融実務において、ポートフォリオ全体の損益変動リスクを最小化するような資産取引戦略(ヘッジ戦略)を見つけ出すことは重要です。この「損失リスク最小化問題」と呼ばれる問題への対応として、「リスク中立評価」に基づいて資産構成を調整するというアプローチ(いわゆる、デルタ・ヘッジ等)が挙げられます。一定の条件のもとで「ポートフォリオの合計損益がゼロ」となるヘッジ戦略を求める手法です。
こうした方法は、必要な計算が比較的容易なことから実務で広く使われています。もっとも、取引コストなど、実際の実務に存在する幾つかの要素について、定量的に取り込むことが難しい点が長らく課題とされてきました。
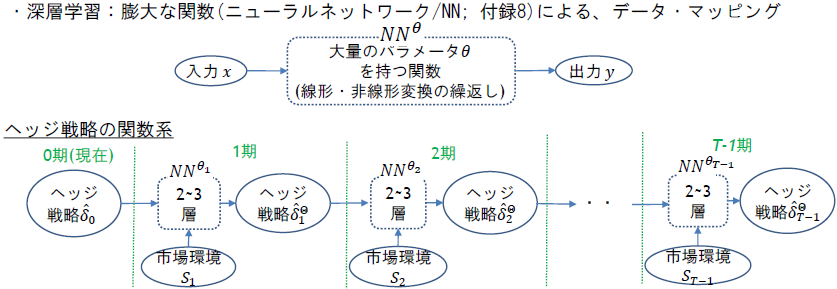
近年、深層学習を活用することで、リスク中立評価を用いずに損失リスクを最小化するヘッジ戦略を直接求める「ディープ・ヘッジング」という枠組みがBuehler, Gonon, Teichmann, and Wood (2019) (参考文献 5)によって提案されました。
ディープ・ヘッジングは、取引コスト等の現実的な要素を加味してヘッジ戦略を算出することができるため、金融実務及びファイナンス研究において、新しい有力な分析手法となりうることが期待されており、実務家、研究者の双方で関心が高まっています。
この手法では、まず、ヘッジ戦略を大量のパラメータを持つ関数であるニューラルネットワークを用いてモデル化します。次に、深層学習を用いて、損失リスクを最小化するようなモデルのパラメータの値を計算、すなわち、モデルに学習させます。学習結果が、損失リスクを最小化するヘッジ戦略になるというわけです。

指定討論者の筬島靖文氏(SMBC日興証券)は、ディープ・ヘッジングは金融実務家も非常に注目しているが、テクニカルな文献が中心で、全体像が見えにくくなっている。このため、当該技術の要点をまとめた本研究は非常に有用である、と評価しました。そのうえで、ディープ・ヘッジングの特性を、数値例を交えつつ紹介しました。
ディープ・ヘッジングの技術は、学習データの準備やリスクの適切な計測方法など、課題は少なくありません。しかし、ヘッジ戦略の算出においてこれまで無視されてきた取引コスト等の影響を分析する手段となりうるため、近年研究が盛んに行われ大きく発展しています。将来的には、金融機関の資産・負債管理(ALM)やストレステストなど、幅広いリスク管理への応用も展望されます。
5. 閉会挨拶

閉会挨拶で貝塚正彰(日本銀行理事)は、最近の経済分析において利用可能なデータが増大する一方、分析手法も機械学習等の新たな広がりを見せる中、両者の組み合わせにより伝統的な分析では見えなかった関係性が見出されてきており、今後も両者のバランスのとれた発展が期待されると指摘しました。
また、ファイナンス技術の発展はリスク管理の高度化をもたらす一方、金融システム面での新たなリスクにつながる可能性もあると指摘し、中央銀行は、こうしたリスクに対応するため、最先端の分析技術をキャッチアップしていくことが重要であると述べて、ワークショップを締めくくりました。
本ワークショップの議事要旨と発表論文は、金融研究所のディスカッション・ペーパーとして公表し、本ワークショップのウェブサイトにも掲載する予定です。 [2022年ファイナンス・ワークショップへのリンク]
なお、ここに掲載した所属・肩書は、本ワークショップ開催時点のものです。
【参考文献】
文献末尾の番号をクリックすると、本文に戻ります。
-
日本銀行「オルタナティブデータ分析」
https://www.boj.or.jp/research/bigdata/index.htm/
(1) - Devlin Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. (2018). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” arXiv:1810.04805. (2)
- Sakaji, Hiroki, Satoshi Sekine, and Shigeru Masuyama (2008). "Extracting causal knowledge using clue phrases and syntactic patterns," 7th International Conference on Practical Aspects of Knowledge Management, pp.111-122. (3)
- Lundberg, Scott and Su-In Lee (2017). "A unified approach to interpreting model predictions," Advances in Neural Information Processing Systems, pp. 4765-4774. (4)
- Buehler, Hans, Lukas Gonon, Josef Teichmann, and Ben Wood (2019). "Deep hedging," Quantitative Finance, 19(8), pp. 1271-1291. (5)